Same words, different worlds
Everyone in the humanitarian sector uses the same words. The problem is that nobody means quite the same thing. And with AI systems about to reason over that data, the gap between shared vocabulary and shared meaning has never mattered more.

A few weeks ago in Geneva, at the Humanitarian Networks and Partnerships Week, my colleague Will and I, ran a session on AI-enabled disaster management systems. At our stand, we presented the Montandon open taxonomy and its implementation as a STAC extension, a way to catalogue and cross-reference disaster data from multiple sources using a shared, open schema. Organisations arrived carrying their own systems, their own classification standards, their own databases. I expected the usual wariness, the quiet scepticism of a sector that has seen too many tools come and go. Instead, they leaned in. They asked questions. They wanted to know more. That surprised me, and it made me wonder what they were really looking for.
Since coming back, I've been turning that moment over. The problem they recognise, even if they don't always frame it this way, is not that they lack vocabulary. Everyone in the humanitarian sector knows what a flood is, what "affected" means, what displacement looks like. The words are shared. The meanings, it turns out, are not.
One earthquake, three models
Consider something as seemingly straightforward as an earthquake. In the GDACS and GLIDE system, widely used for disaster identification, an earthquake is a single class: "EQ." One code, one concept. In the EM-DAT classification maintained by CRED, the same event unfolds into a tree of sub-classes: ground movement, tsunamis, liquefaction, surface rupture, each with its own branch. In the UNDRR-ISC Hazard Information Profiles, updated just this year, everything has been consolidated into a single earthquake class, with all related phenomena folded into one entry, while tsunamis, regardless of their trigger, are now grouped into their own separate class entirely. Three systems, three conceptualisations of what an earthquake is, of where it stops and where the next phenomenon begins. These are not labelling differences. They reflect fundamentally different models of what exists in the domain.
The 2025 UNDRR-ISC update is actually interesting in this regard, because it introduces what they call "chapeau" classifiers, umbrella classes like "flooding" that deliberately group coastal, riverine, flash, glacial lake outburst, and other flood types under a single heading. The intent is precisely to enable better cross-mapping between systems. It is, in other words, an acknowledgment that the fragmentation has become a problem worth solving.
The consequences of not solving it are quiet but real. When different organisations assess the same disaster using subtly different definitions of 'affected,' the resulting figures diverge in ways that are difficult to reconcile even with careful aggregation rules. The numbers that flow into planning documents carry the appearance of precision, but rest on conceptual foundations that were never fully aligned.
Beyond vocabulary
So what would solving it actually require? Not another glossary, and not another classification system either. In 1993, the computer scientist Tom Gruber proposed a definition that still resonates: an ontology is an explicit specification of a conceptualisation. That sounds abstract, but the practical implication is quite concrete. An ontology doesn't just list terms and their definitions. It specifies the concepts, the relationships between them, and crucially, the constraints on their coherent use. Committing to an ontology means accepting that certain combinations of assertions are valid and others are not, that you cannot meaningfully claim something is both a "flash flood" and a "coastal flood" in the same event description, for instance, or that "affected" must include or exclude certain categories of people depending on the agreed definition.
This is what Gruber calls ontological commitment, and it is fundamentally different from having a shared vocabulary. A glossary says "here is what we mean by these words." An ontology says "here is what we commit to, and here are the boundaries we will not cross." The humanitarian sector has plenty of the former. What it lacks, so far, is the latter.
And there is a reason for that, which is not technical. Classification is an act of power. The definition of "affected" is not an academic question, it determines who gets counted, which in turn determines where funding flows. The organisation whose definition prevails shapes the allocation of resources. During my week at HNPW, I discussed this with colleagues at IFRC, GDACS, and OCHA: everyone acknowledged the problem, everyone was working on their own piece of it, but the question of who should coordinate a shared effort remained unanswered. It seems to me that this is naturally the role of the UN system, and the UNDRR-ISC Hazard Information Profiles are encouraging evidence that such coordination can work: 330 authors and reviewers from over 150 organisations contributed to the 2025 update. But the process remains an expert-led, institution-mediated consultation, published as a static document. Compare that to how STAC evolved, through a public repository, through community sprints, through anyone being able to open an issue or propose an extension. The UNDRR work is consultative from the top down. What the sector may need is something collaborative from the bottom up, where organisations don't just receive a standard but help build it, track its evolution, and commit to it because it is genuinely theirs.

Syntax is not semantics
This spectrum from glossary to taxonomy to ontology also maps onto a concrete technical gap. Most data catalogues today, including STAC, use JSON Schema for validation. JSON Schema is excellent at expressing structural constraints: what type a field must be, which values are allowed, which properties are required. But it operates at the syntactic level, not the semantic one. It can merely say "if the hazard is classified as a flood, then the sub-type must be drawn from this specific set of flood categories." It cannot enforce that "affected_direct plus affected_indirect must equal affected_total." It cannot express that a cascading event, an earthquake triggering a tsunami triggering a flood, requires an explicit declaration of the triggering chain rather than three independent entries. These are constraints about meaning and coherence, and they live beyond what a type system can reach.
Technologies do exist to bridge this gap. JSON-LD adds a semantic context layer to JSON documents, allowing each property to carry not just a value but a link to a formal definition of what that property means. Shape languages like SHACL can express semantic constraints over linked data, the kind of cross-property rules and logical axioms that JSON Schema was never designed for. More recently, frameworks like LinkML have emerged as "polyglot" schema languages that can generate, from a single definition, both JSON Schema for structural validation and semantic annotations for meaning, bridging the two worlds in a single specification. Whether standards like STAC should evolve to incorporate such layers is a challenging path worth exploring.
When machines inherit our ambiguity
AI systems are entering the humanitarian space, and they will reason over exactly this data.
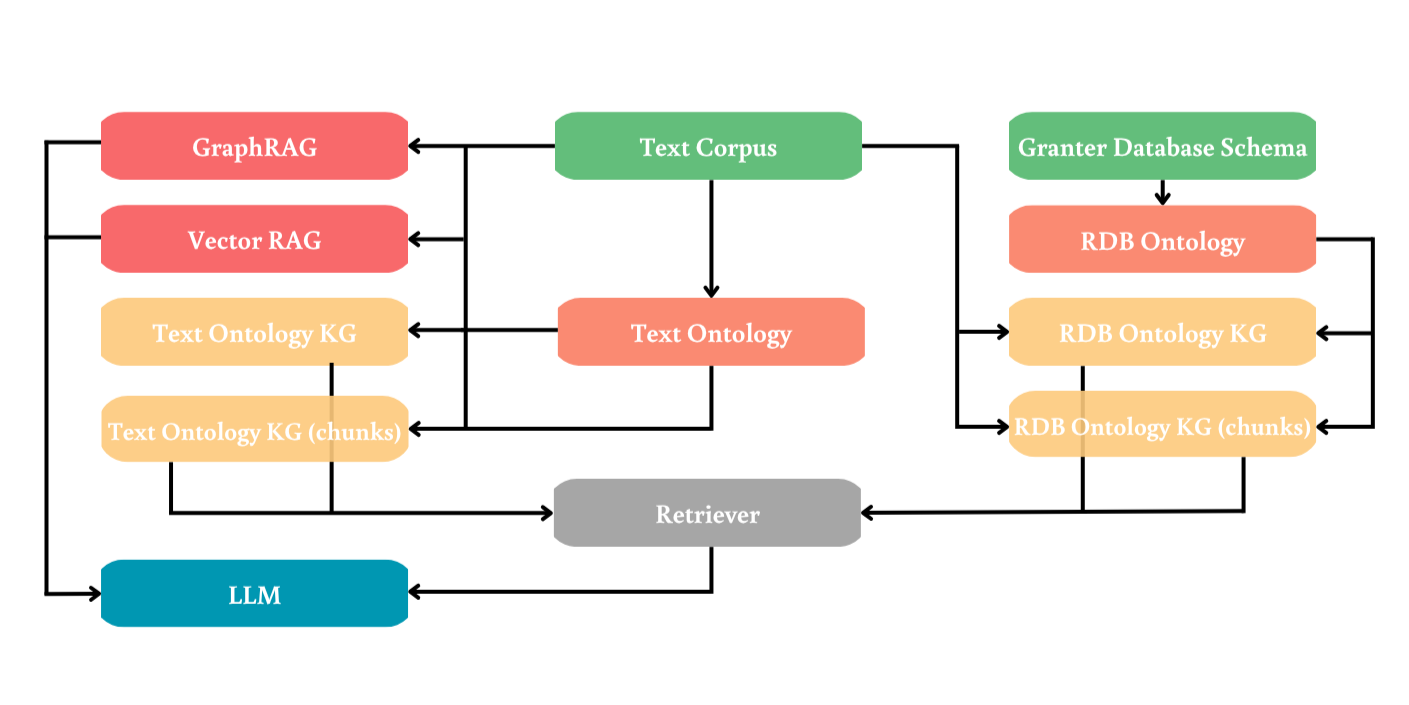
I want to be careful here, because it is tempting to overstate the connection between shared taxonomy and AI performance. But recent research gives us at least one empirical anchor. A 2025 study by da Cruz and colleagues compared different strategies for structuring knowledge in retrieval-augmented generation (RAG) systems, the kind of architecture where a language model retrieves information from an external knowledge base before producing answers. Their finding was clear: when the knowledge base was structured through ontologies rather than treated as raw text for statistical similarity matching, the system performed substantially better. Ontologies, as they put it, serve as blueprints for knowledge construction, capturing domain concepts and relations in a way that flat text embeddings cannot.
The implication is not that AI needs ontology to function, but something more subtle and perhaps more important. When we ask a model to reason across datasets from multiple sources, it will produce answers that are only as consistent as the definitions behind the data it ingests. If "affected" means three different things in three different sources, no amount of statistical sophistication will resolve that ambiguity after the fact. One might argue that future models will learn to disambiguate, but the difficulty here is not polysemy, where context clearly differs, it is near-synonymy in nearly identical contexts: reports using the same words, the same sentence structures, the same surrounding vocabulary, with subtly different semantic boundaries that offer the model almost no signal to distinguish. The model won't flag the contradiction, it will smooth over it, producing confident-sounding answers from semantically incoherent inputs. And that, in a crisis response context, is more dangerous than an obvious error. The alignment has to happen before the data reaches the model, not after.
There is another side to this, which I felt also at HNPW. Our session was organised around three stalls: Detect, Decide, Act. My colleague and I were at the Detect stall, presenting Montandon. But the most intense conversations seemed to happen at the Act stall, where colleagues from IFRC and the Norwegian Refugee Council were asking a different question: how do we trust what an AI tells us enough to act on it? Shared ontology turns out to matter here too, because when the definitions are explicit and agreed upon, an AI's output becomes auditable. A field worker can check whether the system's reasoning follows the constraints the community committed to, rather than having to trust a statistical black box. Ontology doesn't just improve the data going in, it builds trust in the system and makes the decisions coming out legible to the humans who have to act on them.
Invisible foundations
This, I think, is what the people at our HNPW stand were sensing. They weren't just looking for another tool or another standard. They were looking for the foundation on which interoperability, reproducibility, and eventually prediction could be built. The Montandon taxonomy and its STAC extension are working toward exactly that: defining a common vocabulary to catalogue and qualify data so that it gains coherence across sources and across organisations. But the taxonomy is a starting point, not an end. The next step, and one we intend to take, is to move beyond the STAC extension and engage the community on what ontological commitment would actually look like in practice: which constraints matter, which definitions need to be shared, and what the sector is willing to commit to collectively. That conversation has to happen in the open, with the organisations who will live with the result, not behind closed doors.
The humanitarian community has far more pressing concerns right now than data ontology. Budgets are shrinking, funding structures are shifting, and the operational demands of a world with accelerating climate impacts and growing instabilities leave little room for what can feel like an academic exercise. But that is precisely why the question matters. If organisations can save effort by working together on shared definitions in the open, rather than each maintaining their own parallel systems, that is a win for a community that cannot afford to waste resources on duplication.
I have focused here on the humanitarian and disaster management case, because that is where I saw the problem most vividly now. But the challenge is not unique to this sector. Wherever Earth observation data needs to travel from raw acquisition to informed decision, the same gap appears: shared vocabulary without shared meaning, syntactic validation without semantic commitment, classification systems that look interoperable on the surface but diverge underneath. Shortening the path from data to decision, which is ultimately what the Earth Data Value Journey is about, may depend less on better algorithms or faster pipelines than on this quieter, harder work of agreeing on what our words actually mean.
Follow Seeing Earth
New posts straight to your inbox.
Montandon specifications


da Cruz and al. study
